
网站救助计划
1.为阅读体验,本站无任何广告,也无任何盈利方法,站长一直在用爱发电,现濒临倒闭,希望有能力的同学能帮忙分担服务器成本
2.捐助10元及以上同学,可添加站长微信lurenzhang888,备注捐助,网站倒闭后可联系站长领取本站pdf内容
3.若网站能存活下来,后续将会持续更新内容
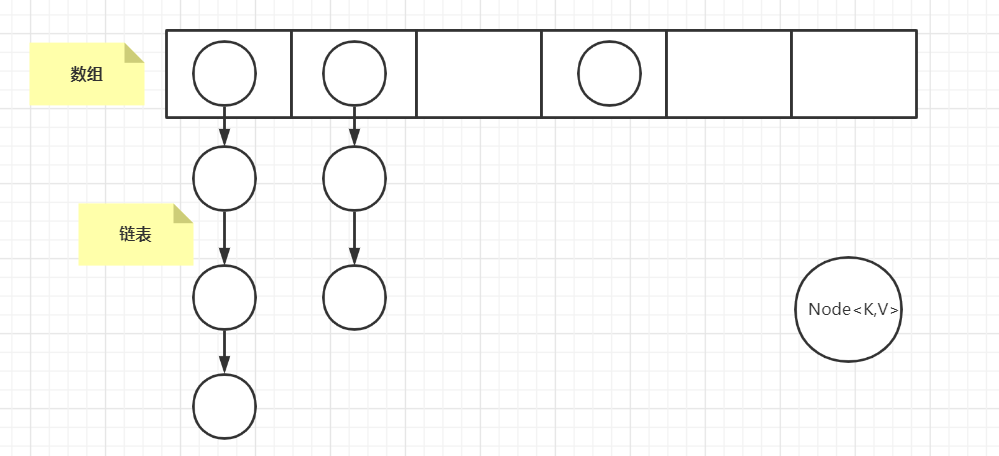
- JDK1.7的底层数据结构(数组+链表)
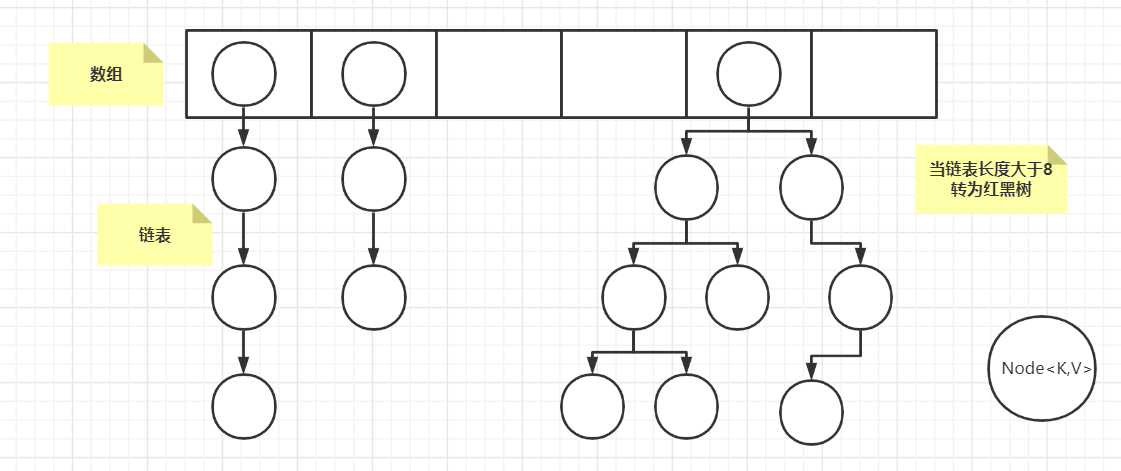
- JDK1.8的底层数据结构(数组+链表)
- JDK1.7的Hash函数
static final int hash(int h){
h ^= (h >>> 20) ^ (h >>>12);
return h^(h >>> 7) ^ (h >>> 4);
}- JDK1.8的Hash函数
static final int hash(Onject key){
int h;
return (key == null) ? 0 : (h = key.hashCode())^(h >>> 16);
}JDK1.8的函数经过了一次异或一次位运算一共两次扰动,而JDK1.7经过了四次位运算五次异或一共九次扰动。这里简单解释下JDK1.8的hash函数,面试经常问这个,两次扰动分别是key.hashCode()与key.hashCode()右移16位进行异或。这样做的目的是,高16位不变,低16位与高16位进行异或操作,进而减少碰撞的发生,高低Bit都参与到Hash的计算。如何不进行扰动处理,因为hash值有32位,直接对数组的长度求余,起作用只是hash值的几个低位。
HashMap在JDK1.7和JDK1.8中有哪些不同点:
| JDK1.7 | JDK1.8 | JDK1.8的优势 | |
|---|---|---|---|
| 底层结构 | 数组+链表 | 数组+链表/红黑树(链表大于8) | 避免单条链表过长而影响查询效率,提高查询效率 |
| hash值计算方式 | 9次扰动 = 4次位运算 + 5次异或运算 | 2次扰动 = 1次位运算 + 1次异或运算 | 可以均匀地把之前的冲突的节点分散到新的桶(具体细节见下面扩容部分) |
| 插入数据方式 | 头插法(先将原位置的数据移到后1位,再插入数据到该位置) | 尾插法(直接插入到链表尾部/红黑树) | 解决多线程造成死循环的问题 |
| 扩容后存储位置的计算方式 | 重新进行hash计算 | 原位置或原位置+旧容量 | 省去了重新计算hash值的时间 |
本站链接:https://www.mianshi.online,如需勘误或投稿,请联系微信:lurenzhang888
点击面试手册,获取本站面试手册PDF完整版