
1.为阅读体验,本站无任何广告,也无任何盈利方法,站长一直在用爱发电,现濒临倒闭,希望有能力的同学能帮忙分担服务器成本
2.捐助10元及以上同学,可添加站长微信lurenzhang888,备注捐助,网站倒闭后可联系站长领取本站pdf内容
3.若网站能存活下来,后续将会持续更新内容
在说Redis集群前,先说下为什么要使用Redis集群,Redis单机版主要有以下几个缺点:
- 不能保证数据的可靠性,服务部署在一台服务器上,一旦服务器宕机服务就不可用。
- 性能瓶颈,内存容量有限,处理能力有限
Redis集群就是为了解决Redis单机版的一些问题,Redis集群主要有以下几种方案
- Redis 主从模式
- Redis 哨兵模式
- Redis 自研
- Redis Clustert
下面对这几种方案进行简单地介绍:
Redis主从模式
Redis单机版通过RDB或AOF持久化机制将数据持久化到硬盘上,但数据都存储在一台服务器上,并且读写都在同一服务器(读写不分离),如果硬盘出现问题,则会导致数据不可用,为了避免这种问题,Redis提供了复制功能,在master数据库中的数据更新后,自动将更新的数据同步到slave数据库上,这就是主从模式的Redis集群,如下图
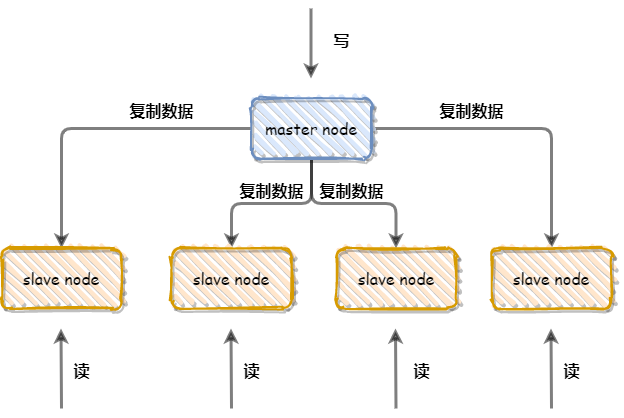
主从模式解决了Redis单机版存在的问题,但其本身也不是完美的,主要优缺点如下:
优点:
- 高可靠性,在master数据库出现故障后,可以切换到slave数据库
- 读写分离,slave库可以扩展master库节点的读能力,有效应对大并发量的读操作
缺点:
- 不具备自动容错和恢复能力,主节点故障,从节点需要手动升为主节点,可用性较低
Redis 哨兵模式
为了解决主从模式的Redis集群不具备自动容错和恢复能力的问题,Redis从2.6版本开始提供哨兵模式
哨兵模式的核心还是主从复制,不过相比于主从模式,多了一个竞选机制(多了一个哨兵集群),从所有从节点中竞选出主节点,如下图

从上图中可以看出,哨兵模式相比于主从模式,主要多了一个哨兵集群,哨兵集群的主要作用如下:
- 监控所有服务器是否正常运行:通过发送命令返回监控服务器的运行状态,处理监控主服务器、从服务器外,哨兵之间也相互监控。
- 故障切换:当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换master。同时那台有问题的旧主也会变为新主的从,也就是说当旧的主即使恢复时,并不会恢复原来的主身份,而是作为新主的一个从。
哨兵模式的优缺点:
优点:
- 哨兵模式是基于主从模式的,解决可主从模式中master故障不可以自动切换故障的问题。
缺点:
- 浪费资源,集群里所有节点保存的都是全量数据,数据量过大时,主从同步会严重影响性能
- Redis主机宕机后,投票选举结束之前,谁也不知道主机和从机是谁,此时Redis也会开启保护机制,禁止写操作,直到选举出了新的Redis主机。
- 只有一个master库执行写请求,写操作会单机性能瓶颈影响
Redis 自研
哨兵模式虽然解决了主从模式存在的一些问题,但其本身也存在一些弊端,比如数据在每个Redis实例中都是全量存储,极大地浪费了资源,为了解决这个问题,Redis提供了Redis Cluster,实现了数据分片存储,但Redis提供Redis Cluster之前,很多公司为了解决哨兵模式存在的问题,分别自行研发Redis集群方案。
客户端分片
客户端分片是把分片的逻辑放在Redis客户端实现,通过Redis客户端预先定义好的路由规则(使用哈希算法),把对Key的访问转发到不同的Redis实例中,查询数据时把返回结果汇集。如下图

客户端分片的优缺点:
优点:Redis实例彼此独立,相互无关联,每个Redis实例像单服务器一样运行,非常容易线性扩展,系统的灵活性很强。
缺点:
- 客户端sharding不支持动态增删节点。服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整。
- 运维成本比较高,集群的数据出了任何问题都需要运维人员和开发人员一起合作,减缓了解决问题的速度,增加了跨部门沟通的成本。
- 在不同的客户端程序中,维护相同的路由分片逻辑成本巨大。比如:java项目、PHP项目里共用一套Redis集群,路由分片逻辑分别需要写两套一样的逻辑,以后维护也是两套。
代理分片
客户端分片的最大问题就是服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整。
为了解决这个问题,代理分片出现了,代理分片将客户端分片模块单独分了出来,作为Redis客户端和服务端的桥梁,如下图
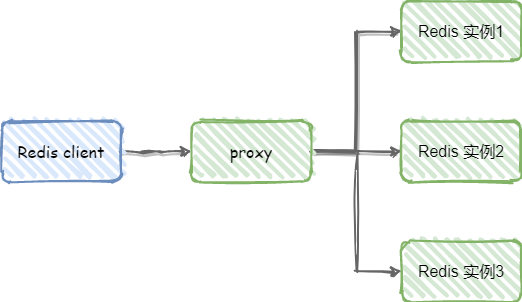
代理模式的优点:解决了服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整的问题。缺点是由于Redis客户端的每个请求都经过代理才能到达Redis服务器,这个过程中会产生性能损失。
常见的代理分片有Twitter开源的Redis代理Twemproxy和豌豆荚自主研发的Codis
Redis Cluster
前面介绍了为了解决哨兵模式的问题,各大企业提出了一些数据分片存储的方案,在Redis3.0中,Redis也提供了响应的解决方案,就是Redist Cluster。
Redis Cluster是一种服务端Sharding技术,Redis Cluster并没有使用一致性hash,而是采用slot(槽)的概念,一共分成16384个槽。将请求发送到任意节点,接收到请求的节点会将查询请求发送到正确的节点上执行。
什么是Redis哈希槽呢?本来不想详细介绍这个的,但面试确实经常问,还是简单说一下,
在介绍slot前,要先介绍下一致性哈希(客户端分片经常会用的哈希算法),那这个一致性哈希有什么用呢?其实就是用来保证节点负载均衡的,那么多主节点,到底要把数据存到哪个主节点上呢?就可以通过一致性哈希算法要把数据存到哪个节点上。
一致性哈希
下面详细说下一致性哈希算法,首先就是对key计算出一个hash值,然后对2^32取模,也就是值的范围在[0, 2^32 -1],一致性哈希将其范围抽象成了一个圆环,使用CRC16算法计算出来的哈希值会落到圆环上的某个地方。
现在将Redis实例也分布在圆环上,如下图(图片来源于网络)
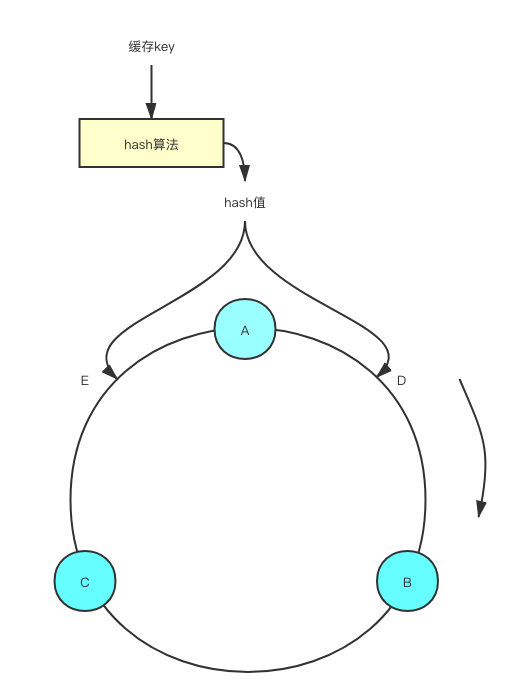
假设A、B、C三个Redis实例按照如图所示的位置分布在圆环上,通过上述介绍的方法计算出key的hash值,发现其落在了位置E,按照顺时针,这个key值应该分配到Redis实例A上。
如果此时Redis实例A挂了,会继续按照顺时针的方向,之前计算出在E位置的key会被分配到RedisB,而其他Redis实例则不受影响。
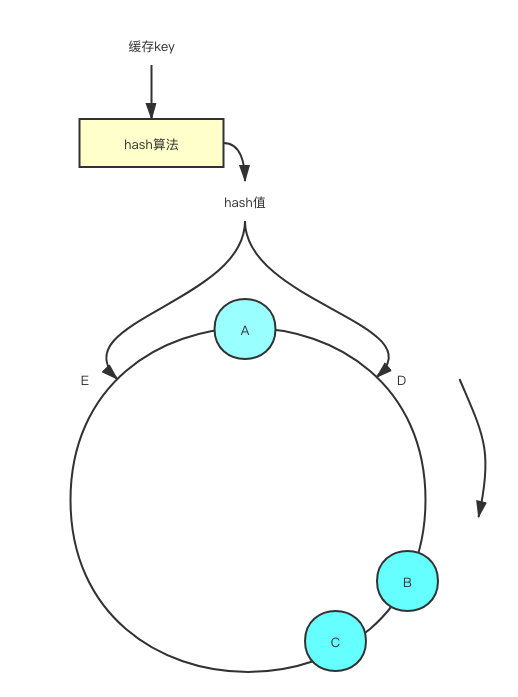
但一致性哈希也不是完美的,主要存在以下问题:当Redis实例节点较少时,节点变化对整个哈希环中的数据影响较大,容易出现部分节点数据过多,部分节点数据过少的问题,出现数据倾斜的情况,如下图(图片来源于网络),数据落在A节点和B节点的概率远大于B节点
为了解决这种问题,可以对一致性哈希算法引入虚拟节点(A#1,B#1,C#1),如下图(图片来源于网络),
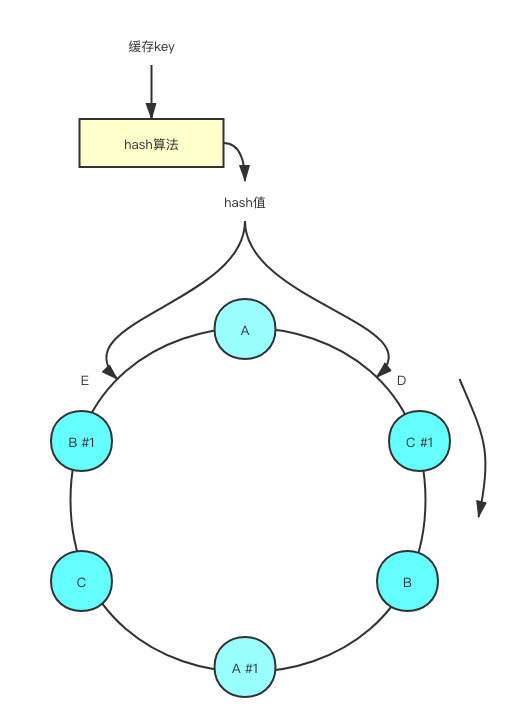
那这些虚拟节点有什么用呢?每个虚拟节点都会映射到真实节点,例如,计算出key的hash值后落入到了位置D,按照顺时针顺序,应该落到节点C#1这个虚拟节点上,因为虚拟节点会映射到真实节点,所以数据最终存储到节点C。
虚拟槽
在Redis Cluster中并没有使用一致性哈希,而引进了虚拟槽。虚拟槽的原理和一致性哈希很像,Redis Cluster一共有2^14(16384)个槽,所有的master节点都会有一个槽范围比如0~1000,槽数是可以迁移的。master节点的slave节点不分配槽,只拥有读权限,其实虚拟槽也可以看成一致性哈希中的虚拟节点。
虚拟槽和一致性哈希算法的实现上也很像,先通过CRC16算法计算出key的hash值,然后对16384取模,得到对应的槽位,根据槽找到对应的节点,如下图。
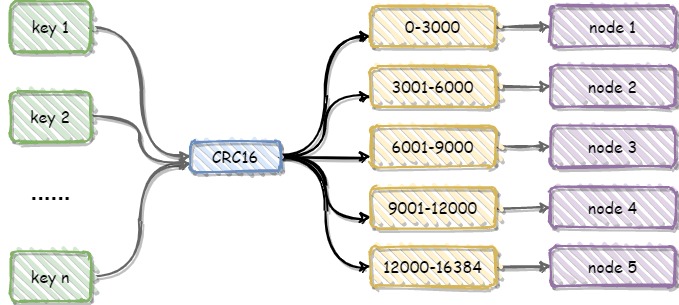
使用虚拟槽的好处:
- 更加方便地添加和移除节点,增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了,当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了,不需要停掉Redis任何一个节点的服务(采用一致性哈希需要增加和移除节点需要rehash)
Redis Cluster 结构
上面介绍了Redis Cluster如何将数据分配到合适的节点,下面来介绍下Redis Cluster结构,简单来说,Redis Cluster可以看成多个主从架构组合在一起,如下图
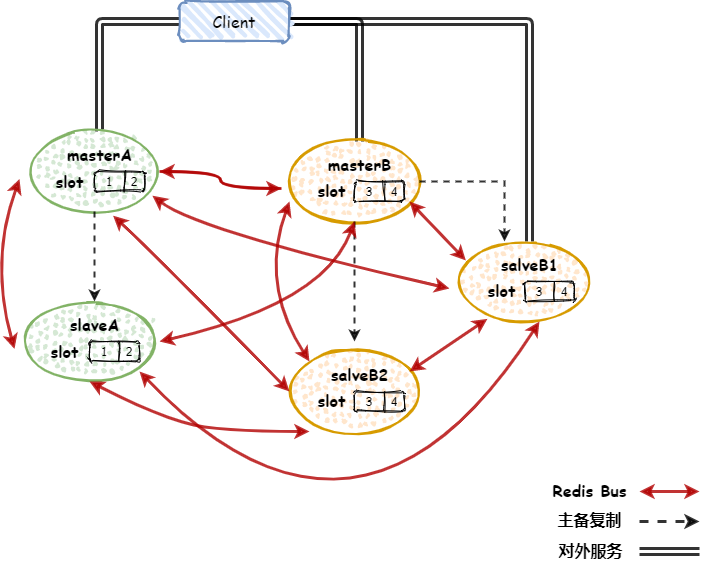
上图看起来比较乱,其实很好理解,上图中一个Redis Cluster有两组节点组成(官方推荐,一般至少三主三从六个节点,画多个节点看起来太乱,所以上图只画了两个主节点),每组节点可以看成一个主从模式,并且每组节点负责的slot不同(假设有4个slot,A组节点负责第1个和第二个slot,B组节点负责第3个和第4个,其中master节点负责写,slave节点负责读)
上图中共有三种线
主备复制的线很好理解,就和主从模式一样,在master库中的数据更新后,自动将更新的数据同步到slave库上
对外服务的线也很好理解,就是外部在对Redis进行读取操作,访问master进行写操作,访问slave进行读操作
Redis Bus的作用相对复杂些,这里简单说下,
首先要知道Redis Cluster是一个去中心化的架构,不存在统一的配置中心,Redis Cluster中的每个节点都保存了集群的配置信息,在Redis Cluster中,这个配置信息通过Redis Cluster Bus进行交互,并最后达成一致性。
配置信息的一致性主要依靠PING/PONG,每个节点向其他节点频繁的周期性的发送PING/PONG消息。对于大规模的集群,如果每次PING/PONG 都携带着所有节点的信息,则网络开销会很大。此时Redis Cluster 在每次PING/PONG,只包含了随机的一部分节点信息。由于交互比较频繁,短时间的几次交互之后,集群的状态也会达成一致。
当Cluster 结构不发生变化时,各个节点通过gossip 协议(Redis Cluster各个节点之间交换数据、通信所采用的一种协议)在几轮交互之后,便可以得知Cluster的结构信息,达到一致性的状态。但是当集群结构发生变化时(故障转移/分片迁移等),优先得知变更的节点会将自己的最新信息扩散到Cluster,并最终达到一致。
其实,上面说了半天也不太容易理解,简单来说Redis Bus是用于节点之间的信息交路,交互的信息有以下几个:
- 数据分片(slot)和节点的对应关系(对应上图中的slot1和slot2在masterA节点上,就是要知道哪个slot在哪个节点上)
- 集群中每个节点可用状态(不断向其他节点发消息看看你挂了没)
- 集群结构发生变更时,通过一定的协议对配置信息达成一致。数据分片的迁移、主备切换、单点master的发现和其发生主备关系变更等,都会导致集群结构变化。(发现有的节点挂了或者有新的节点加进来了,赶紧和其他节点同步信息)
本站链接:https://www.mianshi.online,如需勘误或投稿,请联系微信:lurenzhang888
点击面试手册,获取本站面试手册PDF完整版