
1.为阅读体验,本站无任何广告,也无任何盈利方法,站长一直在用爱发电,现濒临倒闭,希望有能力的同学能帮忙分担服务器成本
2.捐助10元及以上同学,可添加站长微信lurenzhang888,备注捐助,网站倒闭后可联系站长领取本站pdf内容
3.若网站能存活下来,后续将会持续更新内容
很多人都会把数据结构和数据类型混为一谈,包括很多面试官问的时候也没有刻意区分这两个。Redis的数据结构比较多,篇幅有限,这里只重点介绍面试常问的跳跃表。
Redis的数据结构有简单动态字符串、链表、字典、跳跃表、整数集合、压缩列表等。
简单动态字符串:大家都知道,Redis的底层是用C语言编写,但Redis并没有直接使用C语言传统的字符串表示,而是构建了一种名为简单动态字符串的抽象类型。
链表:链表提供了高效的节点重排能力,以及顺序性的节点访问方式,并且可以通过增删节点来灵活地调整链表的长度。链表是列表的底层实现之一。
字典:字典,又称为符号表(symbol table)、关联数组(associativearray)或映射(map),是一种用于保存键值对(key-value pair)的抽象数据结构。字典在Redis中的应用相当广泛,比如Redis的数据库就是使用字典来作为底层实现的,对数据库的增、删、查、改操作也是构建在对字典的操作之上的。
整数集合: 整数集合(intset)是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合键的底层实现。
压缩列表(ziplist):压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。
对象:可能看到这里,很多人在想Redis的数据结构和数据类型的区别,其实上面介绍的是Redis的底层数据结构,但Redis并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象,每种对象都用到了至少一种我们前面所介绍的数据结构,是不是这就和前面对上了。
看到这里很多人会好奇,为什么不直接使用这些底层数据结构,而是要创建对象系统。对象系统主要有以下优点:
- 通过这五种不同类型的对象,Redis可以在执行命令之前,根据对象的类型来判断一个对象是否可以执行给定的命令。
- 我们可以针对不同的使用场景,为对象设置多种不同的数据结构实现,从而优化对象在不同场景下的使用效率。
- 实现了基于引用计数技术的内存回收机制,当程序不再使用某个对象的时候,这个对象所占用的内存就会被自动释放,了解Java虚拟机的垃圾回收机制看到这里是不是很熟悉。
- Redis还通过引用计数技术实现了对象共享机制,这一机制可以在适当的条件下,通过让多个数据库键共享同一个对象来节约内存。
对象这部分占了比较大的篇幅,其实面试中问的也不多,但为了更方便理解,介绍地多些。顺便看下这些底层数据结构和对象系统的对应关系。

最后介绍下面试中常问的跳跃表。
跳跃表(skiplist):跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。跳跃表作是序集合键的底层实现之一。
和链表、字典等数据结构被广泛地应用在Redis内部不同,Redis只在两个地方用到了跳跃表,一个是实现有序集合键,另一个是在集群节 点中用作内部数据结构,除此之外,跳跃表在Redis里面没有其他用途。
跳跃表本质上采用的是一种空间换时间的策略,是一种可以可以进行二分查找的有序链表,跳表在原有的有序链表上增加了多级索引,通过索引来实现快速查询。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
这是一个原始的有序列表,时间复杂度为O(n)。

为了提高查找效率,可以对链表建立一级索引,如下图,在之前找到11这个元素需要遍历6个节点,现在需要5个。链表越长,效率提升越明显。

为了继续提高查找效率可以继续增加索引
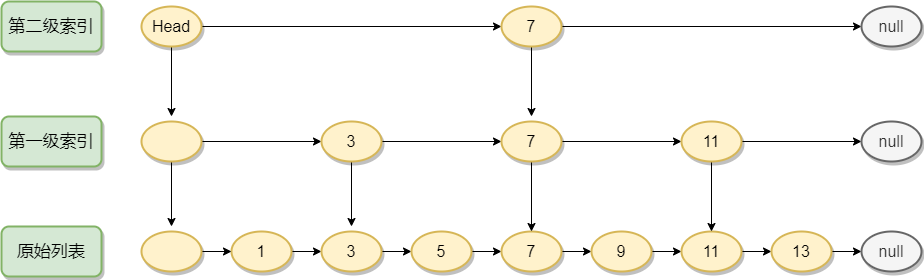
对于理想的跳表,每向上一层索引节点数量都是下一层的1/2,跳表的时间复杂度为o(logn),空间复杂度为o(n),虽然是空间换时间的策略,这里举例存储的只是数字,如果是存储比较大的对象,浪费的空间就不值得一提了,因为索引结点只需要存储关键值和几个指针,并不需要存储对象。
跳表相比于红黑树的优点(redis为什么用跳表不同红黑树):
- 内存占用更少,自定义参数化决定使用多少内存
- 查询性能至少不比红黑树差
- 简单更容易实现和维护
上面这三个优点是我在一篇博客中看到,这个问题redis作者本人也回应过。我这蹩脚的英文水平就不翻译了,以免跑偏了。
- They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
- A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
- They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
最后,说下Redis中的跳跃表和普通的跳跃表有什么区别?
- Redis中的跳跃表分数(score)允许重复,即跳跃表的key允许重复,如果分数重复,还需要根据数据内容来进字典排序。普通的跳跃表是不支持的。
- 第1层链表不是一个单向链表,而是一个双向链表。这是为了方便以倒序方式获取一个范围内的元素。
- 在Redis的跳跃表中可以很方便地计算出每个元素的排名。
篇幅有限,关于跳表的实现细节就不过多介绍了,有兴趣的同学可以自行了解,本小节部分内容参考《Redis设计与实现》
本站链接:https://www.mianshi.online,如需勘误或投稿,请联系微信:lurenzhang888
点击面试手册,获取本站面试手册PDF完整版