
1.为阅读体验,本站无任何广告,也无任何盈利方法,站长一直在用爱发电,现濒临倒闭,希望有能力的同学能帮忙分担服务器成本
2.捐助10元及以上同学,可添加站长微信lurenzhang888,备注捐助,网站倒闭后可联系站长领取本站pdf内容
3.若网站能存活下来,后续将会持续更新内容
如果出现网络问题断开,会自动重连,并且支持断点续传,接着上次复制的地方继续复制,而不是重新复制一份。
下面说下其中的实现细节,首先需要了解replication buffer和replication backlog
replication buffer:主库连接的每一个从库的对应一个 replication buffer,主库执行完每一个操作命令后,会将命令分别写入每一个从库所对应的 replication buffer
replication backlog:replication backlog 是一个环形区域,大小可以通过 repl-backlog-size参数设置,并且和 replication buffer不同的是,一个主库中只有一个 replication backlog。
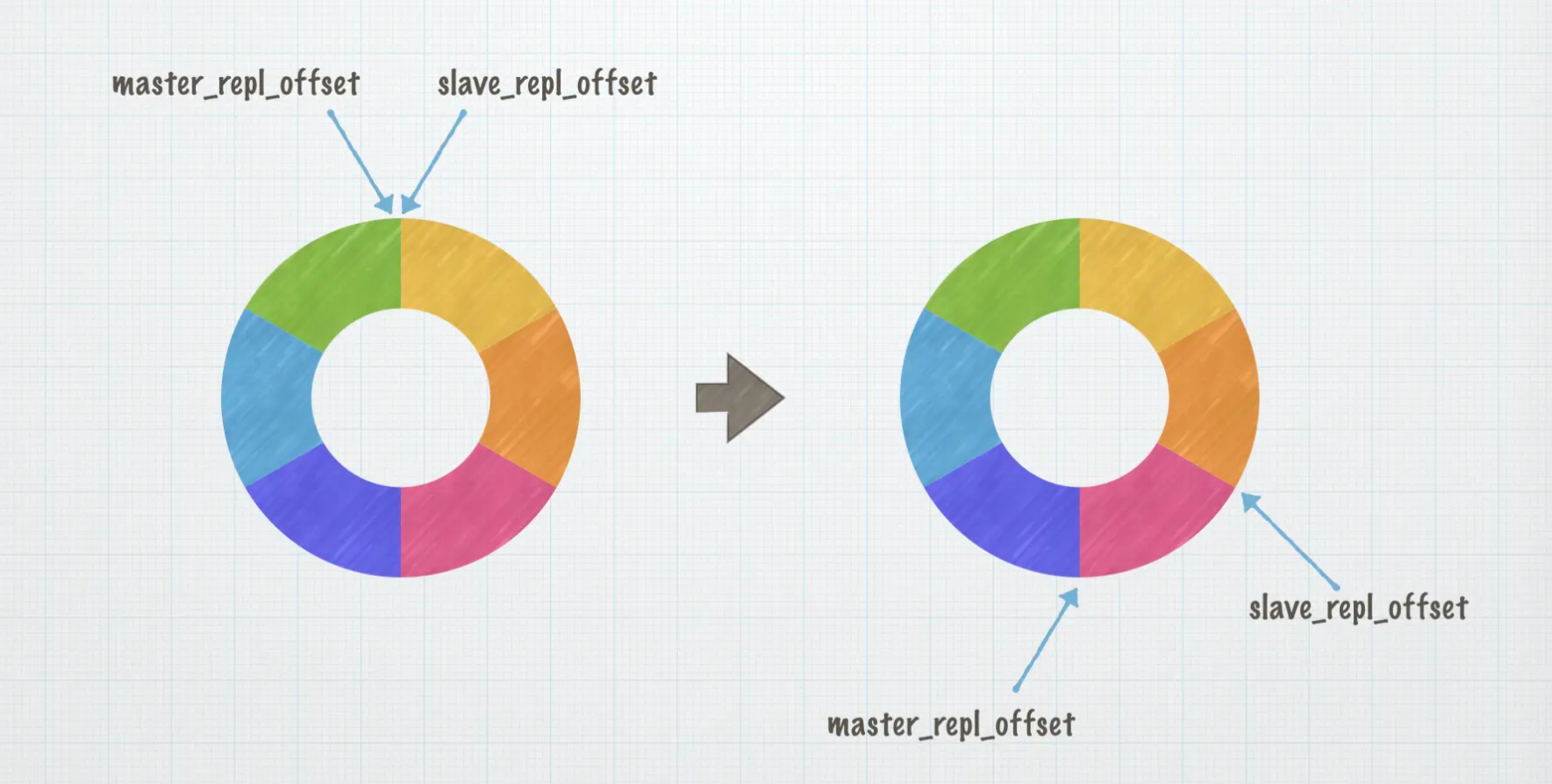
主库会通过 master_repl_offset 记录写入的位置,从库会通过 slave_repl_offset 记录自己读取的位置,这里的位置也叫做偏移量。
刚开始复制数据的时候,上述两者的值相同,且都位于初始位置。每当主库向 replication backlog 写入一个操作,master_repl_offset 就会增加 1,从库复制完操作命令后,slave_repl_offset 也会增加 1。
正常情况下,slave_repl_offset 会跟着 master_repl_offset 变化,两者保持一个小的差距,或者相等。
如果主从库之间的网络连接中断,从库便无法继续复制主库的操作命令,但是主库依然会向 replication backlog 中写入操作命令。
当网络恢复之后,从库会继续向主库请求同步数据,主库通过slave_repl_offset知道从库复制操作命令的位置。这个时候,主库只需要把 master_repl_offset 和 slave_repl_offset 之间的操作命令同步给从库就可以了。
但是前面提到 replication backlog 是一个环形结构,如果网络中断的时间过长,随着主库不断向其中写入操作命令,master_repl_offset 不断增大,就会有从库没有复制的操作命令被覆盖。如果出现这种情况,就需要重新进行全量复制了。
为了避免全量复制的情况,可以通过修改 repl-backlog-size 参数的值,为 replication backlog 设置合适的大小。
这个值需要结合实际情况来设置,具体思路是:从命令在主库中产生到从库复制完成所需要的时间为 t,每秒钟产生的命令的数量为 c,命令的大小为 s,这个值不能低于他们的乘积。考虑到突发的网络压力以及系统运行过程中可能出现的阻塞等情况,应该再将这个值乘以 2 或者更多。
此处参考博客:https://juejin.cn/post/7017827613544546335
本站链接:https://www.mianshi.online,如需勘误或投稿,请联系微信:lurenzhang888
点击面试手册,获取本站面试手册PDF完整版