
1.为阅读体验,本站无任何广告,也无任何盈利方法,站长一直在用爱发电,现濒临倒闭,希望有能力的同学能帮忙分担服务器成本
2.捐助10元及以上同学,可添加站长微信lurenzhang888,备注捐助,网站倒闭后可联系站长领取本站pdf内容
3.若网站能存活下来,后续将会持续更新内容
这是面试的高频题,需要好好掌握,这个问题是没有最优解的,只能数据一致性和性能之间找到一个最适合业务的平衡点
首先先来了解下一致性,在分布式系统中,一致性是指多副本问题中的数据一致性。一致性可以分为强一致性、弱一致性和最终一致性
- 强一致性:当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值。强一致性对用户比较友好,但对系统性能影响比较大。
- 弱一致性:系统并不保证后续进程或者线程的访问都会返回最新的更新过的值。
- 最终一致性:也是弱一致性的一种特殊形式,系统保证在没有后续更新的前提下,系统最终返回上一次更新操作的值。
大多数系统都是采用的最终一致性,最终一致性是指系统中所有的副本经过一段时间的异步同步之后,最终能够达到一个一致性的状态,也就是说在数据的一致性上存在一个短暂的延迟。
如果想保证缓存和数据库的数据一致性,最简单的想法就是同时更新数据库和缓存,但是这实现起来并不现实,常见的方案主要有以下几种:
- 先更新数据库,后更新缓存
- 先更新缓存,后更新数据库
- 先更新数据库,后删除缓存
- 先删除缓存,后更新数据库
乍一看,感觉第一种方案就可以实现缓存和数据库一致性,其实不然,更新缓存是个坑,一般不会有更新缓存的操作。因为很多时候缓存中存的值不是直接从数据库直接取出来放到缓存中的,而是经过一系列计算得到的缓存值,如果数据库写操作频繁,缓存也会频繁更改,所以更新缓存代价是比较大的,并且更改后的缓存也不一定会被访问就又要重新更改了,这样做无意义的性能消耗太大了。下面介绍删除缓存的方案
先更新数据库,后删除缓存
这种方案也存在一个问题,如果更新数据库成功了,删除缓存时没有成功,那么后面每次读取缓存时都是错误的数据。
解决这个问题的办法是删除重试机制,常见的方案有利用消息队列和数据库的日志
利用消息队列实现删除重试机制,如下图
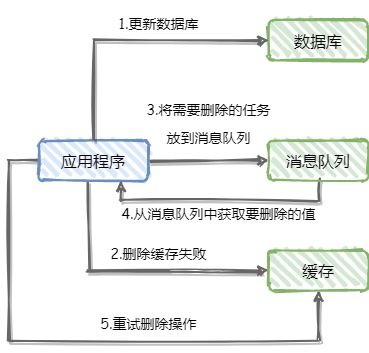
步骤在图中写的已经比较清除了,这里简单说下为什么使用消息队列,消息队列可以保证写到队列中的消息在成功消费之前不会消失,并且在第4步中获取消息时只有消费成功才会删除消息,否则会继续投递消息给应用程序,符合消息重试的要求。
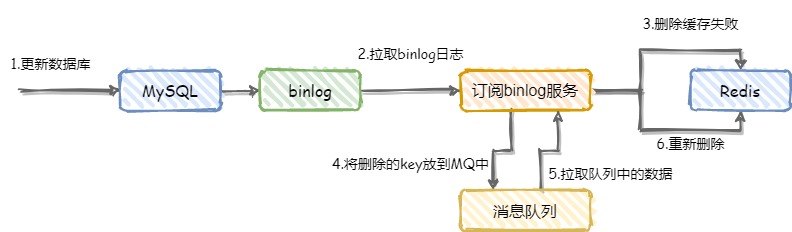
但这个方案也有一些缺点,比如系统复杂度高,对业务代码入侵严重,这时可以采用订阅数据库日志的方法删除缓存。如下图
先删除缓存,后更新数据库
这种方案也存在一些问题,比如在并发环境下,有两个请求A和B,A是更新操作,B是查询操作
- 假设A请求先执行,会先删除缓存中的数据,然后去更新数据库
- B请求查询缓存发现为空,会去查询数据库,并把这个值放到缓存中
- 在B查询数据库时A还没有完全更新成功,所以B查询并放到缓存中的是旧的值,并且以后每次查询缓存中的值都是错误的旧值
这种情况的解决方法通常是采用延迟双删,就是为保证A操作已经完成,最后再删除一次缓存

逻辑很简单,删除缓存后,休眠一会儿再删除一次缓存,虽然逻辑看起来简单,但实现起来并不容易,问题就出在延迟时间设置多少合适,延迟时间一般大于B操作读取数据库+写入缓存的时间,这个只能是估算,一般可以考虑读业务逻辑数据的耗时 + 几百毫秒。
在实际应用中,还是先更新数据库后删除缓存这种方案用的多些。
需要注意的是,无论哪种方案,如果数据库采取读写分离+主从复制延迟的话,即使采用先更新数据库后删除缓存也会出现类似先删除缓存后更新数据库中出现的问题,举个例子
- A操作更新主库后,删除了缓存
- B操作查询缓存没有查到数据,查询从库拿到旧值
- 主库将新值同步到从库
- B操作将拿到的旧值写入缓存
这就造成了缓存中的是旧值,数据库中的是新值,解决方法还是上面说的延迟双删,延迟时间要大于主从复制的时间
本站链接:https://www.mianshi.online,如需勘误或投稿,请联系微信:lurenzhang888
点击面试手册,获取本站面试手册PDF完整版