
网站救助计划
1.为阅读体验,本站无任何广告,也无任何盈利方法,站长一直在用爱发电,现濒临倒闭,希望有能力的同学能帮忙分担服务器成本
2.捐助10元及以上同学,可添加站长微信lurenzhang888,备注捐助,网站倒闭后可联系站长领取本站pdf内容
3.若网站能存活下来,后续将会持续更新内容
这里经常会将jdk1.7中的
ConcurrentHashMap和jdk1.8中的ConcurrentHashMap的实现方式进行对比。
JDK1.7
在JDK1.7版本中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry数组组成,Segment存储的是链表数组的形式,如图所示。
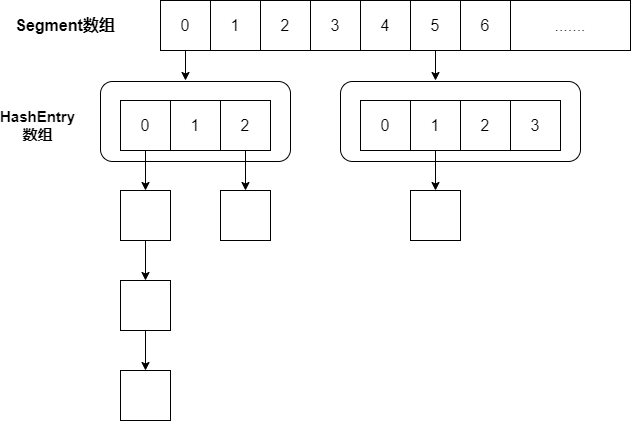
从上图可以看出,ConcurrentHashMap定位一个元素的过程需要两次Hash的过程,第一次Hash的目的是定位到Segment,第二次Hash的目的是定位到链表的头部。两次Hash所使用的时间比一次Hash的时间要长,但这样做可以在写操作时,只对元素所在的segment枷锁,不会影响到其他segment,这样可以大大提高并发能力。
JDK1.8
JDK1.8不在采用segment的结构,而是使用Node数组+链表/红黑树的数据结构来实现的(和HashMap一样,链表节点个数大于8,链表会转换为红黑树)
如下图所示
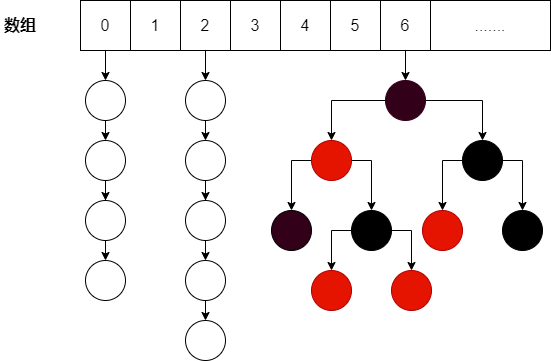
从上图可以看出,对于ConcurrentHashMap的实现,JDK1.8的实现方式可以降低锁的粒度,因为JDLK1.7所实现的ConcurrentHashMap的锁的粒度是基于Segment,而一个Segment包含多个HashEntry。
本站链接:https://www.mianshi.online,如需勘误或投稿,请联系微信:lurenzhang888
点击面试手册,获取本站面试手册PDF完整版